Hadoop背后的数学
自从Nathan Marz同学写了那篇著名的How to beat the CAP theorem的Blog,以及Storm发布之后,俨然成为了技术界新偶像。顺着他本人的blog,翻了一下他过去几年的写的技术文章,发现老美的牛人们都爱总结,能够把技术实践提升到理论高度,然后抽象出新的设计和产品,比起我等只能每天苦逼苦逼应对实际需求的人来说,还是强出很多。我自己觉得那么多年,虽然觉得做什么都能做了,但是现在还是只能谈到模仿,做不到提炼总结和超越。
和著名的CAP的那篇Blog,Nathan Marz还有很多其他非常有料值得一读的博客,与其在国内的各种Hadoop大会上听大家泛泛而谈架构,还不如多看看老外们总结下来的技术博呢,比如这篇The mathematics behind Hadoop-based systems,比起大家简单列列机器数字来说,有价值得多。
我曾经写过,数学对于称为一名优秀的程序员是很重要的,但这不一定意味着一定要是多高深的数学。Nathan的这篇Blog用到的数学只有初中难度,但是的确写明白了我们遇到的很多Estimation以及集群数量预估的实际问题,我想一定也有很多人用hadoop但是和我们一样,对于很多机器数量或者workflow的管理是很粗放的,相信这篇blog对很多人都会有用,所以把它翻译成中文,全文如下
基于Hadoop的系统背后的数学
我希望一年之前我就知道这些。现在,根据一些简单的数学,我就可以回答:
- 为什么在我将处理能力翻倍之后,我的workflow的速度没有翻倍?
- 为什么10%的任务失败率会导致我的运行时间上升到原来的300%?
- 如果通过优化了我的workflow的运行时间的30%导致运行时间下降了80%?
- 我的集群中到底需要多少机器可以满足性能和容错的需要?
所有这些问题都可以通过这样一个简单的等式干净地回答:
运行时间(Runtime) = 额外开销(Overhead) / (1-{处理一小时数据需要的时间})
我们很快就可以推导出这个等式。首先,让我们简单地讨论一下什么是我所说的“基于Hadoop的系统”1。Hadoop的一个常见的用例,就是通过运行一个workflow来处理来连续进入的流数据。这个工作流运行一个”while(true)”的循环,然后每个workflow的迭代,都处理自从上个迭代依赖累积的数据。
下面的这些分析的灵感可以在一个简单的示例中概括出来。假如说你有一个workflow需要运行12小时,然后它会在每个迭代中处理12个小时的数据。然后假如说你加强了这个workflow去做一些额外的分析,然后你估计你在当前的这个workflow中需要多花两个小时来处理。然后麻烦来了。你的workflow增加的运行时间可能远超过两小时。它可能增加了10个小时,100个小时,或者这个workflow可能呈螺旋式上升地在每个迭代中花费越来越多的时间知道无限。
为什么?
问题在于,你将处理12个小时数据的workflow的运行时间增加到了14个小时。这意味着当下一次workflow运行的时候,有14小时的数据需要处理。既然下一个迭代有更多的数据,他要花费更多时间运行。这意味着下一个迭代会有更多的数据,等等。
为了确定什么时候运行时间,让我们做一些简单的算术。首先,让我们写下一个只有一个迭代的workflow的运行时间的等式
运行时间 = 额外开销 + {处理一小时数据的时间} * {多少小时的数据}
额外开销(Overhead)指的是花费在workflow上的任何常数项时间。例如,开始一个job需要的时间会计入额外开销。使用distributed cache来分发文件的时间会计入额外开销。你会把任何独立于数据规模的时间花费放到“额外开销”的分类中去。
“处理一小时数据的时间”指的是workflow中的动态时间。这是你忽视那些额外开销,花费在处理实际数据上的时间。如何一小时的数据会增加你半小时的运行时间上,这个值应该是0.5。如果一小时的数据会增加你一小时的运行时间,这是值就是2。
为了简洁,让我们把上面那个等式通过变量来重新写一下:
T = O + P * H
为了确定workflow的稳定的运行时间,我们需要找到workflow的运行时间在哪个点上正好等于累积了的需要处理的数据量。为了做这个,我们可以简单地插入 T=H 来求解T:
T = O + P * T
T = O / (1 - P)
这就是我之前展示的等式。你可以看到,一个workflow的稳定的运行时间是和workflow中的额外开销呈线性比例的。所以如果你可以将额外开销减少25%,那么你的workflow运行时间就会减少25%。然而,一个workflow的稳定运行时间和动态处理的速率“P”不是呈线性比例的。这背后的隐含含义就是每为集群加入一台机器带来的性能提升是在减少的。
通过这个等式,我们可以回答我在文章开始时候写下的问题了。让我们一起来过一些这些问题:
为什么在我将处理能力翻倍之后,我的workflow的速度没有翻倍?
将你的机器数翻倍,会将你的“处理一小时数据需要的时间”减少50%2。这个的效果和你的运行时间的关系是完全依赖于之前的P值的。让我们用数学来展示一下。假如说你的workflow在集群的机器数量翻倍之前的运行时间是“T1”,翻倍之后是“T2”。这给了我们两个等式:
T1 = O / (1-P)
T2 = O / (1 - P/2)
那么性能加速就会是 T2/T2,新的运行时间和旧的运行时间的比值。这给到我们
T2 / T1 = (1 - P) / (1 - P/2)
T2 / T1 = 1 - P / (2 - P)
对这个式子作图,我们可以得到如下的图,其中原始的P在x轴上,性能加速在y轴3上:
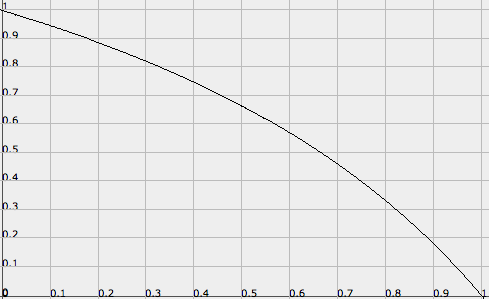
这个图说明了一切。如果你的P非常高,比如说,需要54分钟来处理一小时的数据,那么将你的集群数量翻倍会使得你新的运行时间是原来的18%,足足有82%的性能加速!这是一个非常违背直觉的结论 — — 我强烈推荐读者们仔细思考这种情况出现的背后的机制。
然后,如果你之前的P没有那么高(例如,需要6分钟的动态运行时间来处理1小时的数据),那么将集群数量翻倍对于运行时间几乎没有效果 — — 可能只有类似6%。由于运行时间被额外开销所主导,这是很合乎情理的,动态运行时间在运行时间中占得很小。
为什么10%的任务失败率会导致我的运行时间上升到原来的300%?
这个问题解释了workflow稳定性的属性。在一个大集群中,你总是会有不同的机器故障,所以任务失败率的峰值不会干掉mission critical系统的性能是非常重要的。关于这个问题的分析会和上一个问题看起来非常相似,除了我们会将动态运行时间变差而不是提高它之外。10%的任务失败率意味着我们需要多运行11%的任务来处理完我们的数据4。由于任务依赖于我们所拥有的数据量,这意味着,我们的“处理一小时数据需要的时间”会上升11%。类似于上一个问题,让我们将T1作为没有任务失败所需要的运行时间,T2作为有任务失败的运行时间
T1 = O / (1 - P)
T2 = O / (1 - 1.11*P)
T2 / T1 = (1 - P) / (1 - 1.11*P)
对此作图,我们得到:
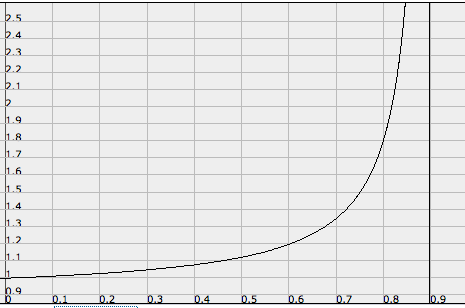
(译著: 上图中X轴为P值,Y轴为花费时间增加的比例)
你可以看到,任务失败对于运行时间的影响在你的集群有“额外容量”减少的情况下戏剧性地增长。所以让保持你的P低是非常重要的。我们可以看到你的P越高,由于任务失败率的增加,你就更有可能进入“毁灭循环”的风险5。
如果通过优化掉我的workflow的运行时间的30%而导致运行时间下降了80%?
这个问题是使得我真正找出workflow的运行时间的模型。我曾在一个workflow中有一个荒谬的瓶颈,导致了大概10小时的额外开销6,然后整个workflow的运行时间大概是30小时。在我优化了这个瓶颈(大约占据了30%的运行时间)之后,运行时间像石头一样坠落,最终稳定在6小时(减少了80%)。使用我们的模型,我们可以确定为什么这发生了:
30 = O / (1 - P)
6 = (O - 10) / (1 - P)
O = 12.5, P = 0.58
所以那10小时,占据了workflow中的80%的额外开销,这解释了整个的性能提升。
我的集群中到底需要多少机器可以满足性能和容错的需要?
这基本上是一个费效比分析的练习。我们可以看到,通过增加集群中机器数据来提高性能到回报在减少,而一旦P(“处理一小时数据需要的时间”)下降到30分钟以下(0.5),通过增加机器获得的性能提升是次线性的7。我们也同样看到将P保持得低是很重要得,不然任务失败的增加或者其他的任务使用集群,会严重影响你的运行时间。所以,你需要运行一些数据来确定对你的应用最佳的机器数量8。
你应该在Twitter上follow我。
更新:看看本文的后续内容
1 事实上,这个等式适用于任何批量处理连续数据流的系统。
2 这里假设你的处理是完全分布式的,并且没有持有任何中心点,这对于一个基于Hadoop的workflow来说通常是真的。一个可能的例外是,你所有的tasks都通过一个中心的数据库进行通信。事实上,增加更多的机器会在额外开销(更多的机器去处理)以及数据处理速率(mapper需要将数据分发到更多的reducer中去)有少量的不利影响。对于这个分析的目的来说,我们可以忽略这些。
3 该图通过FooPlot生成。
4 比如说我们通过100个task来处理数据,现在,当你运行这些task的时候,其中有10个会失败。当你重新运行这10个的时候,9个会成功,还有1一个会失败。所以你实际运行了111个task而不是100个,这意味着task的数量增加了11%。
5 或者其他的运行在集群上的东西,比如一次性的查询或者其他的workflow。
6 这是由于Berkeley DB在ext3的文件系统上会生成很多碎片。
7 事实上,我没有展示这个,但是你可以通过模型来自己推导。我把这个作为一个练习留给读者。
8 如果你需要的话,你可以让这个模型变得更加全面。比如,这个模型没有区分新进入的数据和已经存在需要被查询的数据(并且在每个迭代中都会增加)。这个变量必然会影响到你的长期扩展需求,记住它是非常重要的。对于那些知识对于这些workflow的性能有获得一个直觉的目的来说,这不是必须的。
originally posted at medium.com/@xuwenhao/hadoop%E8%83%8C%E5%90%8E...
| NAV | NEXT ON THE BENCH | DATE | |
|---|---|---|---|
| PREV | Yet Another Year | 2012 | ← |
| NEXT | 永远买你能买得起的最好的生产工具 | 2012 | → |
He'd just put the board on your desk and walk away.
So - that's what this is.